

Nội dung trùng lặp có nghĩa là toàn bộ hoặc một phần nội dung có thể xuất hiện trên nhiều URL. Kết quả là các công cụ tìm kiếm không biết trang nào sẽ hiển thị trong kết quả. Thoạt nhìn, dường như không có gì phải lo lắng vì trang web của bạn vẫn đang xếp hạng tốt.
Nhưng Duplicate Content có thể dẫn đến giảm thứ hạng đáng kể và do đó vấn đề này hoàn toàn đáng quan tâm và cần kiểm tra để khắc phục kịp thời.
Trong bài viết này, tôi sẽ đề cập đến các bản duplicate là gì, tại sao chúng xuất hiện, làm thế nào để loại bỏ chúng và sử dụng công cụ nào.
Tại sao trùng lặp nội dung lại tác động tiêu cực đến SEO?
Chúng tôi đã làm rõ rằng các bản copy làm tổn thương SEO của bạn. Bây giờ hãy tìm hiểu tại sao điều này xảy ra. Việc giảm thứ hạng thường xuất phát từ một số vấn đề chính:
- Khả năng hiển thị trên công cụ tìm kiếm giảm. Vì nhiệm vụ chính của các công cụ tìm kiếm là cung cấp dữ liệu phù hợp nhất, nên hiếm khi chúng hiển thị hai trang giống nhau ở kết quả. Họ buộc phải chọn chỉ một trang từ các bản duplicate của bạn, một trang có liên quan nhất. Và do đó, khả năng hiển thị của mỗi bản duplicate bị ảnh hưởng.
- Pha loãng giá trị liên kết. Hãy tưởng tượng rằng cùng một bài viết có sẵn trên hai URL khác nhau. Do đó, tất cả các backlink và chia sẻ sẽ được phân chia giữa hai bài viết này khi một số độc giả đang liên kết đến URL đầu tiên và các bài viết khác - đến bài thứ hai. Và như chúng ta biết backlink là một trong những yếu tố xếp hạng chính, điều này sẽ ảnh hưởng đến khả năng hiển thị tìm kiếm.
- Lãng phí ngân sách thu thập dữ liệu. Thu thập dữ liệu ngân sách là số lượng URL Googlebot có thể và muốn thu thập thông tin trong một khoảng thời gian nhất định. Điều đó có nghĩa là số lượng trang chỉ mục trình thu thập thông tin một lần bị giới hạn.
Các kiểu trùng lặp phổ biến nhất
Có hàng tá lý do tại sao các bản duplicate có thể xuất hiện. Nếu tôi trình bày tất cả chúng trong bài viết này, bạn sẽ mất vài ngày để đọc nó. Đó là lý do tại sao, tôi sẽ đề cập đến những cái phổ biến nhất.
Phiên bản "Www" & không "www" + phiên bản "http" & "https"
Nếu trang web của bạn có thể truy cập cả ở phiên bản www và không www, bạn có hai trang web giống hệt nhau với các bản s duplicate ao tất cả các trang mà nó có. Điều tương tự cũng xảy ra với các phiên bản http và https. Nếu cả hai đều được các trình thu thập công cụ tìm kiếm lập chỉ mục, một lần nữa bạn sẽ phải đối mặt với vấn đề trùng lặp nội dung.
Ví dụ: http://seothetop.com và http://www.seothetop.com
Nếu site của bạn hoạt động trên cả 2 địa chỉ này sẽ => duplicate content, trường hợp này bạn cần giữ 1 domain, và sử dụng redirect 301 từ cái còn lại sang domain chính.
Bộ lọc và sắp xếp (Filter & Sorting)
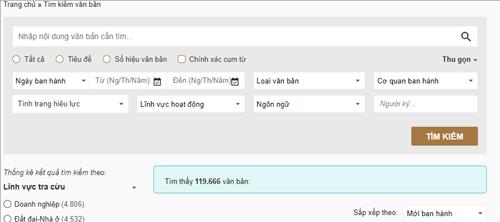
Các yếu tố như sắp xếp và bộ lọc thường gây ra sự trùng lặp. Các kết quả được hình thành trên một trang riêng với URL động. Sự kết hợp của các bộ lọc khác nhau và các tham số sắp xếp dẫn đến việc tạo ra nhiều trang được tạo tự động. Bằng cách bỏ qua lỗi này, bạn để trình thu thập thông tin lập chỉ mục tất cả các trang này. Đó là cách các bản duplicate xuất hiện.
Ví dụ:
https://luatvietnam.vn/tim-van-ban.html?Keywords=abc
https://luatvietnam.vn/tim-van-ban.html?Keywords=xyz
Với trường hợp này bạn nên sử dụng Canonical xác định một trang gốc https://luatvietnam.vn/tim-van-ban.html
 |
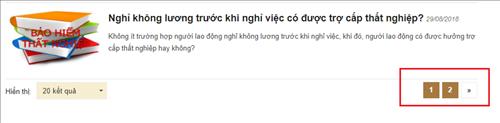
Phân trang (Pagination)
Phân trang cũng tạo ra vấn đề trùng lặp vì tiêu đề và mô tả của tất cả các trang là như nhau. Bạn cần thiết lập phân trang chính xác. Đọc về cách làm điều đó ở cuối bài viết.
 |
Các trang có và không có dấu gạch chéo ở cuối
Một tình huống phổ biến khác mà tôi đã gặp là: các trang web có hai phiên bản có và không có dấu gạch chéo ở cuối URL. Đây là những gì tôi đang nói về:
- com/stores/
- com
Phiên bản cho máy in
Nếu CMS của trang web của bạn tạo các phiên bản trang thân thiện với máy in, nó cũng có thể gây ra việc tạo trùng lặp nếu nhiều phiên bản được lập chỉ mục.
ID phiên (Session)
Để theo dõi hoạt động của khách truy cập, máy chủ của một trang web chỉ định một số cụ thể cho mỗi người dùng trong suốt thời gian truy cập của họ, trong đó mỗi lượt truy cập là một phiên mới.
Một số trang web sử dụng ID phiên trong URL, tạo một trang riêng cho mỗi phiên mới, điều này gây ra sự cố trùng lặp lại.
Vấn đề này đang trở nên lỗi thời vì hầu hết các trang web đang lưu trữ phiên trong cookie.
Sao chép liên kết giới thiệu (Referral link)
Khi người dùng đến trang web thông qua liên kết giới thiệu, trông giống như «? Ref = '», anh ta sẽ được tự động chuyển hướng đến URL chính tắc. Nhưng, thật không may, các nhà phát triển thường quên làm điều này, và do đó các bản s duplicate xuất hiện.
Cách kiểm tra nội dung trùng lặp để khắc phục
Chúng ta đã thảo luận về nội dung trùng lặp là gì, tại sao nó đáng chú ý và tại sao nó xuất hiện. Đã đến lúc tìm hiểu làm thế nào để tìm các bản duplicate và sử dụng công cụ nào.
Kiểm tra với Bảng điều khiển tìm kiếm của Google
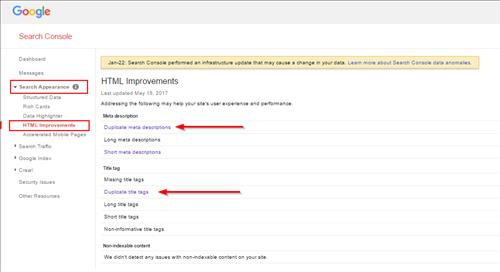
Cách cơ bản để tìm nội dung trùng lặp là Google Webmaster Tools. Đi đến phần Giao diện tìm kiếm và nhấp vào Cải tiến HTML. Nếu có trùng lặp trên trang web của bạn, chúng sẽ được hiển thị tại các mô tả meta trùng lặp và thẻ Tiêu đề trùng lặp . Thật không may, công cụ này không hiển thị tất cả các loại trùng lặp.
Nếu cùng một mục được đặt trong hai danh mục khác nhau, thì tiêu đề và mô tả có thể khác nhau một phần và các mục trùng lặp đó không được hiển thị tại các công cụ Google Webmaster. Do đó phương pháp này là tuyệt vời để xác định sự tồn tại của vấn đề nội dung trùng lặp, nhưng nó không phải là phương pháp tốt nhất để phân tích chuyên sâu.
 |
Kiểm tra với ứng dụng thu thập dữ liệu Screamfrog
Các chương trình như vậy giúp các chuyên gia thực hiện kiểm toán trang web kỹ thuật nhanh chóng, toàn diện. Họ thu thập dữ liệu trang web của bạn giống như một robot công cụ tìm kiếm và điều này làm cho chúng trở thành cách tốt nhất để phát hiện các vấn đề SEO, bao gồm cả các bản duplicate. Netpeak Spider và SEO Screamfrog là những công cụ thu thập thông tin nổi tiếng nhất.
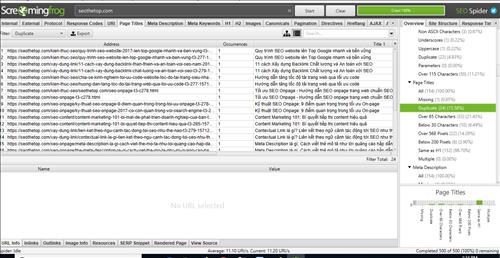 |
| Kiểm tra trùng lặp các thẻ meta với công cụ miễn phí screemfrog |
Sử dụng phần mềm Serpstat
Bạn cũng có thể sử dụng mô-đun Kiểm toán của Serpstat. Tạo một dự án và thiết lập các tham số kiểm toán mong muốn. Sau một thời gian, bạn sẽ nhận được một danh sách các lỗi được chia cho cả loại lỗi và mức độ ưu tiên.
Chuyển đến phần thẻ Meta của mô-đun Kiểm toán để xem danh sách các trang có thẻ tiêu đề hoặc mô tả giống hệt nhau. Đây là cách nó trông như thế nào: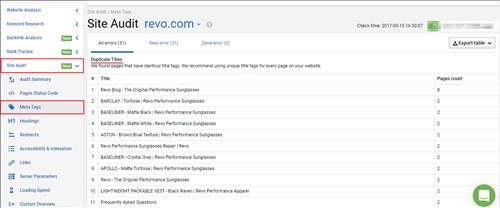 |
Kiểm tra trùng lặp Thủ công
Vâng, bạn cũng có thể tìm kiếm các bản duplicate theo cách thủ công, hơn nữa là trang web của bạn khá nhỏ. Có một số toán tử tìm kiếm để giúp bạn.
Sử dụng site:yourwebsite.com để lấy danh sách tất cả các trang trên trang web của bạn được Google lập chỉ mục.
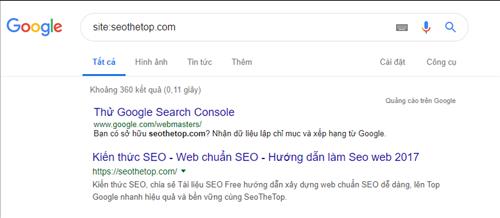 |
Bây giờ bạn có thể tự kiểm tra kết quả để xác định các bản duplicate. Hoặc nếu bạn muốn kiểm tra xem trang này hoặc trang đó có trùng lặp hay không, hãy sử dụng toán tử sau: site: mysite.com intitle: tiêu đề bạn đang kiểm tra
Cách khắc phục sự cố trùng lặp nội dung
Khi nói đến vấn đề trùng lặp nội dung, nói "sửa chữa", chúng tôi có nghĩa là hiển thị cho Google một số trang giống hệt nhau là trang gốc. Và có một số cách phổ biến nhất để làm điều đó:
Set Redirect 301
Trong hầu hết các trường hợp, cách tốt nhất để hiển thị trang nào là trang gốc là đặt redirect 301 từ trang trùng lặp sang trang gốc. Chuyển hướng 301 nói với bot "Này, trang này được chuyển vĩnh viễn sang trang mới, xóa nó khỏi chỉ mục và chuyển quyền liên kết và mức độ liên quan đến trang mới". Đó là giải pháp tốt nhất cho việc chuẩn hóa:
Xem xét và xử lý trùng lặp với các trường hợp sau:
- phiên bản www hoặc không www cho site;
- phiên bản http và https;
- trang có và không có "/" ở cuối;
- trùng lặp vô dụng khác.
 |
Sử dụng thẻ rel "canonical"
Một cách khác để sửa các bản duplicate là thẻ rel "canonical". Không giống như chuyển hướng 301, chúng tôi sử dụng thẻ chuẩn khi yêu cầu trang trùng lặp và không thể xóa được. Vì vậy, giả sử chúng ta có hai trang tương tự, trang gốc là trang không sử dụng sorting, trong khi các bản duplicate là các trang được phân loại từ giá thấp đến cao và ngược lại. Tất nhiên, tất cả các trang này đều cần thiết nhưng như chúng ta đã biết các bản duplicate làm tổn thương SEO của chúng ta. Và đây là nơi thẻ "canonical" có ích. Nó là phù hợp nhất cho:
- trang sorting;
- trang filter;
- trang utm;
- các trang cần thiết khác.
Hãy quay lại ví dụ trang sandals. Bạn cần đặt
<link rel = "canonical" href = "https://onlinestore.com/shoes/sandals/" />
Trên trang
https://onlinestore.com/shoes/sandals/?sort_min_price
Do đó, khi trình thu thập thông tin truy cập trang sandals được sắp xếp theo bộ lọc "từ giá thấp đến cao", nó hiểu rằng trang danh mục được ưa thích và bạn sẽ tránh được vấn đề trùng lặp nội dung.
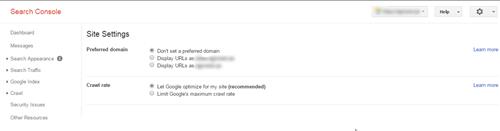
Chọn tên miền ưa thích tại các công cụ Google Webmaster
Tại Google Search Console, bạn có thể chọn tên miền ưa thích: có hoặc không có www. Đó là một thay thế cho chuyển hướng 301. Nhưng, bạn nên nhớ rằng mọi thứ bạn đặt tại công cụ Google Webmaster chỉ hoạt động cho Google. Do đó, tốt hơn là đặt chuyển hướng 301 để hiển thị tất cả các công cụ tìm kiếm hiện có phiên bản trang web nào được ưa thích.
 |
Thẻ meta Robot
Cách cuối cùng nhưng không phải là cách ít nhất để khắc phục vấn đề trùng lặp nội dung là thẻ meta "noindex, follow". Nó cho phép các công cụ tìm kiếm thu thập dữ liệu một trang cụ thể nhưng không lập chỉ mục cho nó. Sử dụng thẻ "noindex, follow" để đảm bảo rằng các công cụ tìm kiếm sẽ không bỏ qua các liên kết trên các trang trùng lặp. Đây là giải pháp tốt nhất cho các trang thân thiện với máy in, vd
Đặt thẻ rel = "prev" và rel = "next" để phân trang
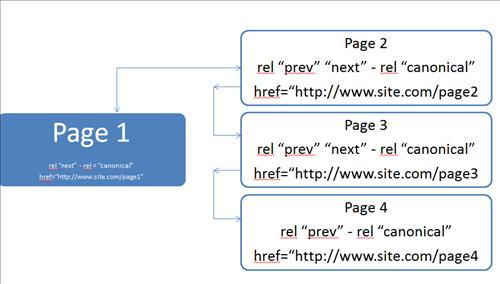
Vào năm 2011, Google đã thêm một cặp thẻ rel = "prev" và rel = "next" nhằm chỉ ra mối quan hệ giữa các URL thành phần trong một chuỗi được phân trang. Sử dụng thẻ rel = "prev" và rel = "next" để giúp Google hiểu rằng đây không phải là bản duplicate mà là phân trang. Tag rel = "prev" là viết tắt của trang trước, trong khi rel = "next" cho trang tiếp theo. Đây là cách nó sẽ trông như thế nào:
Trang 1: <link rel="next" href="https://domain/category/page2" />
Trang 2: <link rel="prev" href="https://domain/category" /> và
<link rel="next" href="https://domain/category/page3" />
Trang 3: <link rel="prev" href="https://domain/category/page2" /> và
<link rel="prev" href="https://domain/category/page4" />
 |
Tóm kết
Nội dung trùng lặp là một vấn đề nghiêm trọng dẫn đến giảm thứ hạng và do đó mất lưu lượng truy cập. Có một loạt các lý do khác nhau tại sao các bản duplicate có thể xuất hiện và điều quan trọng là nên kiểm tra định kỳ và loại bỏ chúng kịp thời.
Xin lưu ý rằng vấn đề nội dung trùng lặp là một chủ đề rất lớn, trong bài viết này, tôi chỉ đề cập đến những điều cơ bản. Hơn nữa, tất cả các cách khắc phục vấn đề này chỉ là khuyến nghị vì phần lớn phụ thuộc vào tình huống cụ thể khi nói đến trùng lặp. Tôi hy vọng rằng bạn đã tìm thấy phần nội dung này hữu ích trong bài viết này.
SeoTheTop
Nguồn tham khảo:









