Các Search Engine hay công cụ tìm kiếm là các máy trả lời. Chúng tồn tại để khám phá, hiểu và tổ chức nội dung của internet để cung cấp các kết quả có liên quan nhất cho những câu hỏi của người tìm kiếm.
Để hiển thị trong kết quả tìm kiếm, nội dung của bạn cần phải được hiển thị trước tiên cho các công cụ tìm kiếm. Nó được cho là phần quan trọng nhất của SEO: Nếu trang web của bạn không thể tìm thấy, bạn sẽ không bao giờ được hiển thị trong SERPs (Search Engine Results Page). |
| Trước tiên Google phải truy cập được vào site sau đó thu thập, đánh chỉ mục và xếp hạng |
Nội dung:
Công cụ tìm kiếm hoạt động như thế nào?
- Crawling là gì?
- Indexing là gì?
- Ranking là gì
- Lưu ý: Trong SEO, không phải tất cả các công cụ tìm kiếm đều giống nhau
Thu thập thông tin: Công cụ tìm kiếm có thể tìm thấy trang web của bạn không?
Cho công cụ tìm kiếm biết cách thu thập dữ liệu website của bạn
Lập chỉ mục: Các công cụ tìm kiếm hiểu và ghi nhớ site của bạn như thế nào?
- Tôi có thể xem cách trình thu thập thông tin của Googlebot nhìn thấy các trang của tôi không?
- Các trang có bị xóa khỏi chỉ mục không?
Xếp hạng: Công cụ tìm kiếm xếp hạng URL như thế nào?
- Công cụ tìm kiếm muốn gì?
- Vai trò liên kết trong SEO
- Vai trò Nội dung trong SEO
- RankBrain là gì?
- Chỉ số tương tác: tương quan, nhân quả hoặc cả hai?
- Sự tiến hóa của kết quả tìm kiếm
Công cụ tìm kiếm Google hoạt động như thế nào?
Công cụ tìm kiếm có ba chức năng chính:
- Thu thập thông tin(Crawling): Lướt Internet tìm nội dung, xem qua mã/nội dung cho mỗi URL mà họ tìm thấy.
- Lập Chỉ mục(Indexing): Lưu trữ và sắp xếp nội dung được tìm thấy trong quá trình thu thập thông tin. Khi trang được lập chỉ mục, trang đang chạy sẽ được hiển thị dưới dạng kết quả cho các truy vấn có liên quan.
- Xếp hạng(Ranking): Cung cấp các phần nội dung sẽ trả lời tốt nhất với truy vấn của người tìm kiếm. Xếp thứ tự các kết quả tìm kiếm bằng cách hữu ích nhất cho một truy vấn cụ thể.
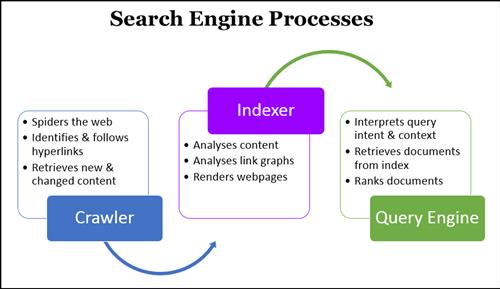 |
| 3 bước xử lý cơ bản của công cụ tìm kiếm |
Crawling là gì?
Thu thập thông tin, là quá trình khám phá trong đó các công cụ tìm kiếm gửi một nhóm rô bốt (được gọi là trình thu thập thông tin hoặc trình thu thập thông tin) để tìm nội dung mới và được cập nhật. Nội dung có thể khác nhau - có thể là trang web, hình ảnh, video, PDF, v.v. - nhưng bất kể định dạng, nội dung được phát hiện bằng liên kết.
Bot bắt đầu bằng cách tìm nạp một vài trang web và sau đó theo các liên kết trên các trang web đó để tìm các URL mới. Bằng cách đi theo đường dẫn này, trình thu thập thông tin có thể tìm thấy nội dung mới và thêm nó vào chỉ mục của họ - một cơ sở dữ liệu khổng lồ của các URL được phát hiện - sau này được truy xuất khi người tìm kiếm đang tìm kiếm thông tin rằng nội dung trên URL đó phù hợp.
Indexing là gì?
Công cụ tìm kiếm xử lý và lưu trữ thông tin mà họ tìm thấy trong một chỉ mục, một cơ sở dữ liệu khổng lồ về tất cả nội dung họ đã khám phá và cho là đủ tốt để phục vụ cho người tìm kiếm.
Ranking là gì
Khi ai đó thực hiện tìm kiếm, công cụ tìm kiếm sẽ tìm kiếm chỉ mục của Search Engine cho nội dung có liên quan cao và sau đó xếp thứ tự nội dung đó với hy vọng giải quyết truy vấn của người tìm kiếm. Thứ tự kết quả tìm kiếm này theo mức độ liên quan được gọi là xếp hạng. Nói chung, bạn có thể giả định rằng một trang web được xếp hạng càng cao thì công cụ tìm kiếm càng tin tưởng rằng trang web đó là giải quyết được mong muốn của người tìm kiếm.
Có thể chặn trình thu thập dữ liệu của công cụ tìm kiếm từ một phần hoặc toàn bộ trang web của bạn hoặc hướng dẫn các công cụ tìm kiếm tránh lưu trữ các trang nhất định trong chỉ mục của chúng. Mặc dù có thể có lý do để thực hiện việc này, nếu bạn muốn nội dung của mình được tìm thấy bởi người tìm kiếm, trước tiên bạn phải đảm bảo rằng trình thu thập thông tin có thể truy cập được và có thể lập chỉ mục được. Nếu không, các trang của bạn sẽ không thể xuất hiện trong trang kết quả tìm kiếm.
Lưu ý: Trong SEO, không phải tất cả các công cụ tìm kiếm đều giống nhau
Nhiều người mới bắt đầu tự hỏi về tầm quan trọng của các công cụ tìm kiếm cụ thể. Hầu hết mọi người đều biết rằng Google có thị phần lớn nhất, nhưng tầm quan trọng của việc tối ưu hóa đối với Bing, Yahoo và các search engine khác là gì? Sự thật là mặc dù sự tồn tại của hơn 30 công cụ tìm kiếm web lớn, cộng đồng SEO thực sự chỉ chú ý đến Google. Tại sao? Câu trả lời ngắn gọn là Google là nơi đại đa số người tìm kiếm trên web. Nếu chúng tôi bao gồm Google Images, Google Maps và YouTube (thuộc tính của Google), hơn 90% tìm kiếm trên web xảy ra trên Google - gần gấp 20 lần Bing và Yahoo và phần còn lại.
Thu thập thông tin: Công cụ tìm kiếm có thể tìm thấy trang web của bạn không?
Như bạn vừa biết, đảm bảo rằng trang web của bạn được thu thập thông tin và lập chỉ mục là điều kiện tiên quyết để hiển thị trong SERPs. Trước tiên: Bạn có thể kiểm tra xem có bao nhiêu trang và trang web nào của bạn đã được Google lập chỉ mục bằng cách sử dụng "site:yourdomain.com", toán tử tìm kiếm nâng cao. Ví dụ: site:seothetop.com
Truy cập Google và nhập "site:yourdomain.com" vào thanh tìm kiếm. Điều này sẽ trả lại kết quả mà Google có trong chỉ mục của nó cho website được chỉ định:
 |
Số lượng kết quả mà Google hiển thị không chính xác nhưng nó cung cấp cho bạn ý tưởng vững chắc về các trang được lập chỉ mục trên website của bạn và cách chúng hiện đang hiển thị trong kết quả tìm kiếm.
Để có kết quả chính xác hơn, hãy theo dõi và sử dụng báo cáo Phạm vi chỉ mục trong Google Search Console. Bạn có thể đăng ký tài khoản Google Search Console miễn phí nếu bạn hiện không có tài khoản. Với công cụ này, bạn có thể gửi sơ đồ trang web cho website của mình và theo dõi số trang đã gửi thực sự được thêm vào chỉ mục của Google.
Nếu bạn không hiển thị ở bất kỳ đâu trong kết quả tìm kiếm, có một vài lý do có thể có tại sao:
- Website của bạn hoàn toàn mới và chưa được thu thập thông tin.
- Website của bạn không được liên kết đến từ bất kỳ trang web bên ngoài nào.
- Điều hướng website của bạn khiến rô-bốt khó thu thập dữ liệu một cách hiệu quả.
- Website của bạn chứa một số mã cơ bản được gọi là chỉ thị trình thu thập thông tin đang chặn công cụ tìm kiếm.
- Website của bạn đã bị Google phạt vì các chiến thuật spam.
Nếu trang web của bạn không có bất kỳ trang web nào khác liên kết đến trang web đó, bạn vẫn có thể làm cho nó được lập chỉ mục bằng cách gửi sơ đồ trang web XML(sitemap.xml) của bạn trong Google Search Console hoặc gửi các URL riêng lẻ tới Google theo cách thủ công
Công cụ tìm kiếm có thể xem toàn bộ website của bạn không?
Đôi khi một công cụ tìm kiếm sẽ có thể tìm thấy các phần của website bằng cách thu thập thông tin, nhưng các trang hoặc phần khác có thể bị che khuất vì một lý do nào đó. Điều quan trọng là phải đảm bảo rằng các công cụ tìm kiếm có thể khám phá tất cả nội dung bạn muốn lập chỉ mục và không chỉ trang chủ.
Hãy tự hỏi mình điều này: bot có thể thu thập dữ liệu thông qua trang web của bạn và không chỉ cho trang web đó?
Content của bạn có bị ẩn sau các biểu mẫu đăng nhập không?
Nếu bạn yêu cầu người dùng đăng nhập, điền vào biểu mẫu hoặc trả lời khảo sát trước khi truy cập nội dung nhất định, công cụ tìm kiếm sẽ không thấy các trang được bảo vệ đó. Trình thu thập thông tin chắc chắn sẽ không đăng nhập.
Bạn có dựa vào các biểu mẫu tìm kiếm không?
Robot không thể sử dụng biểu mẫu tìm kiếm. Một số cá nhân tin rằng nếu họ đặt một hộp tìm kiếm trên trang web của họ, công cụ tìm kiếm sẽ có thể tìm thấy mọi thứ mà khách truy cập của họ tìm kiếm.
Văn bản có bị ẩn trong nội dung không phải văn bản không?
Các hình thức phương tiện không phải văn bản (hình ảnh, video, GIF, v.v.) không được sử dụng để hiển thị văn bản mà bạn muốn được lập chỉ mục. Trong khi các công cụ tìm kiếm ngày càng nhận ra hình ảnh tốt hơn, thì không có gì đảm bảo rằng họ sẽ có thể đọc và hiểu nó. Tốt nhất là thêm văn bản trong đánh dấu <HTML> của trang web, cụ thể là thêm mô tả cho hình ảnh vào thuộc tính ATL của thẻ <IMG>, xem hướng dẫn SEO hình ảnh.
Công cụ tìm kiếm có thể theo dõi điều hướng website của bạn không?
Cũng giống như trình thu thập thông tin cần khám phá website thông qua các liên kết từ các trang web khác, nó cần một đường dẫn liên kết trên trang web của riêng bạn để hướng dẫn trang từ trang này đến trang khác. Nếu bạn có một trang mà bạn muốn các công cụ tìm kiếm tìm thấy nhưng nó không được liên kết đến từ bất kỳ trang nào khác, nó như vô hình với công cụ tìm kiếm.
Nhiều website tạo ra sai lầm nghiêm trọng trong việc cấu trúc điều hướng của họ theo những cách không thể truy cập được với các công cụ tìm kiếm, cản trở khả năng của họ được liệt kê trong kết quả tìm kiếm.
Lỗi điều hướng chung có thể khiến trình thu thập không nhìn thấy tất cả trang:
- Điều hướng trên thiết bị di động hiển thị các kết quả khác với điều hướng trên máy tính để bàn
- Bất kỳ loại điều hướng nào trong đó các mục menu không có trong HTML, chẳng hạn như điều hướng bằng JavaScript. Google đã trở nên giỏi hơn trong việc thu thập thông tin và hiểu Javascript, nhưng nó vẫn không phải là một quá trình hoàn hảo . Cách chắc chắn hơn để đảm bảo thứ gì đó được Google tìm thấy, hiểu và lập chỉ mục bằng cách đặt nó vào HTML.
- Cá nhân hóa hoặc hiển thị điều hướng duy nhất cho một loại khách truy cập cụ thể so với những người khác, có thể xuất hiện để che giấu cho trình thu thập thông tin của công cụ tìm kiếm
- Quên để liên kết đến một trang chính trên trang web của bạn thông qua điều hướng của bạn - hãy nhớ, liên kết là các trình thu thập đường dẫn theo các trang mới!
Đây là lý do tại sao điều cần thiết là trang web của bạn có điều hướng rõ ràng và cấu trúc thư mục URL hữu ích.
Kiến trúc thông tin
Kiến trúc thông tin là tổ chức và gắn nhãn nội dung trên một trang web để nâng cao hiệu quả và khả năng nhận biết cho người dùng. Kiến trúc thông tin tốt nhất là trực quan, có nghĩa là người dùng không cần phải suy nghĩ nhiều để đi đến trang web họ muốn hoặc tìm một thứ gì đó.
Trang web của bạn cũng nên có trang 404 (trang không tìm thấy) hữu ích khi khách truy cập nhấp vào liên kết đã chết hoặc URL của không có nội dung. Các trang 404 tốt nhất cho phép người dùng nhấp lại vào trang chủ để họ không thoát ra.
 |
Cho công cụ tìm kiếm biết cách thu thập dữ liệu website
Ngoài việc đảm bảo trình thu thập thông tin có thể tiếp cận các trang quan trọng nhất, cũng cần lưu ý rằng bạn sẽ có các trang trên trang web của mình mà bạn không muốn chúng tìm thấy. Chúng có thể bao gồm những thứ như URL cũ có nội dung mỏng, URL trùng lặp (chẳng hạn như tham số sắp xếp và lọc cho thương mại điện tử), các trang mã khuyến mại đặc biệt, trang dàn dựng hoặc trang thử nghiệm, v.v.
Việc chặn các trang từ công cụ tìm kiếm cũng có thể giúp trình thu thập thông tin ưu tiên các trang quan trọng nhất và tối đa hóa ngân sách thu thập dữ liệu (số trang trung bình mà bot công cụ tìm kiếm sẽ thu thập thông tin trên trang web của bạn).
Chỉ thị trình thu thập thông tin cho phép bạn kiểm soát những gì bạn muốn Googlebot thu thập dữ liệu và lập chỉ mục bằng tệp robots.txt, thẻ meta, tệp sitemap.xml hoặc Google Search Console.
Robots.txt
Các tệp Robots.txt nằm trong thư mục gốc của trang web (ví dụ: yourdomain.com/robots.txt) và đề xuất những phần nào của công cụ tìm kiếm trang web nên và không nên thu thập dữ liệu thông qua chỉ thị robots.txt cụ thể . Đây là một giải pháp tuyệt vời khi cố gắng chặn các công cụ tìm kiếm từ các trang không phải riêng tư trên website của bạn.
Bạn sẽ không muốn chặn các trang riêng tư/nhạy cảm bị thu thập dữ liệu tại đây vì người dùng và bot có thể dễ dàng truy cập file.
- Nếu Googlebot không thể tìm thấy tệp robots.txt cho website ( mã trạng thái HTTP 40X ), Googlebot sẽ thu thập dữ liệu site.
- Nếu Googlebot tìm thấy tệp robots.txt cho một trang web ( mã trạng thái HTTP 20X ), nó sẽ thường tuân thủ các đề xuất và tiếp tục thu thập dữ liệu site.
- Nếu Googlebot không tìm thấy mã trạng thái HTTP 20X hoặc 40X (ví dụ: lỗi máy chủ 501), Googlebot không thể xác định xem bạn có tệp robots.txt hay không và sẽ không thu thập dữ liệu site của bạn.
Chỉ thị meta
Hai loại chỉ thị meta là thẻ meta robot (thường được sử dụng) và thẻ x-robots. Mỗi thẻ cung cấp cho trình thu thập thông tin hướng dẫn mạnh hơn về cách thu thập dữ liệu và lập chỉ mục nội dung của URL.
Thẻ x-robots cung cấp tính linh hoạt và chức năng hơn nếu bạn muốn chặn các công cụ tìm kiếm theo quy mô vì bạn có thể sử dụng cụm từ thông dụng, chặn các tệp không phải HTML và áp dụng các thẻ noindex trên toàn site.
Đây là các tùy chọn tốt nhất để chặn các URL */ riêng tư nhạy cảm hơn từ các công cụ tìm kiếm.
* Đối với các URL rất nhạy cảm, cách tốt nhất là xóa chúng khỏi hoặc yêu cầu đăng nhập an toàn để xem.
Mẹo WordPress: Trong Dashboard > Settings > Reading, đảm bảo hộp " Search Engine Visibility" không được chọn. Điều này chặn các công cụ tìm kiếm truy cập vào trang web của bạn thông qua tệp robots.txt của bạn!
Tránh những cạm bẫy phổ biến này và bạn sẽ có nội dung sạch sẽ, có thể thu thập thông tin cho phép các bot dễ dàng truy cập vào các trang của bạn.
Khi bạn đã đảm bảo trang web của mình đã được thu thập dữ liệu, thứ tự tiếp theo là đảm bảo rằng site đó có thể được lập chỉ mục. Điều đó đúng - chỉ vì trang web của bạn có thể được phát hiện và thu thập dữ liệu bởi một công cụ tìm kiếm không nhất thiết có nghĩa là trang web của bạn sẽ được lưu trữ trong chỉ mục của họ. Đọc tiếp để tìm hiểu về cách lập chỉ mục hoạt động và cách bạn có thể đảm bảo rằng trang web của bạn biến nó thành cơ sở dữ liệu quan trọng này.
Sitemap
Sitemap sơ đồ website: danh sách URL trên site của bạn mà trình thu thập thông tin có thể sử dụng để khám phá và lập chỉ mục nội dung. Một trong những cách dễ nhất để đảm bảo Google đang tìm các trang ưu tiên cao nhất là tạo tệp đáp ứng các tiêu chuẩn của Google và gửi nó thông qua Google Search Console. Trong khi gửi một sitemap không thay thế một điều hướng site tốt, nó sẽ giúp trình thu thập thông tin theo một đường dẫn đến tất cả các trang quan trọng.
Google Search Console
Một số site (phổ biến nhất với thương mại điện tử) có cùng một nội dung trên nhiều URL khác nhau bằng cách nối các thông số nhất định vào URL. Nếu bạn đã từng mua sắm trực tuyến, bạn có thể đã thu hẹp tìm kiếm của mình thông qua các bộ lọc.
Ví dụ: bạn có thể tìm kiếm “giày” trên Amazon và sau đó tinh chỉnh tìm kiếm của mình theo kích thước, màu sắc và kiểu. Mỗi khi bạn tinh chỉnh, URL sẽ thay đổi đôi chút. Làm cách nào để Google biết phiên bản URL nào cần cho người tìm kiếm?
Google thực hiện khá tốt việc tự mình tìm ra URL đại diện, nhưng bạn có thể sử dụng tính năng Tham số URL trong Google Search Console để cho Google biết chính xác cách bạn muốn họ xử lý các trang của bạn.
 |
Indexing: Các công cụ tìm kiếm hiểu và ghi nhớ site như thế nào?
Khi bạn đã đảm bảo site của mình đã được thu thập dữ liệu, tiếp theo là đảm bảo rằng nó có thể được lập chỉ mục. Điều đó đúng - vì site của bạn có thể được phát hiện và thu thập dữ liệu bởi một công cụ tìm kiếm không nhất thiết là trang web của bạn sẽ được lưu trữ trong chỉ mục của họ. Trong phần trước về thu thập thông tin, chúng tôi đã thảo luận cách công cụ tìm kiếm khám phá các trang web của bạn.
Chỉ mục là nơi các trang được khám phá và được lưu trữ. Sau khi trình thu thập thông tin tìm thấy một trang, công cụ tìm kiếm sẽ hiển thị nó giống như trình duyệt. Trong quá trình này công cụ tìm kiếm phân tích nội dung của trang đó. Tất cả thông tin đó được lưu trữ trong chỉ mục của nó.
Tôi có thể xem cách trình thu thập thông tin của Googlebot nhìn thấy các trang của tôi không?
Có, phiên bản được cache của trang sẽ phản ánh ảnh chụp nhanh của lần cuối cùng googlebot thu thập thông tin.
Google thu thập dữ liệu và lưu trữ các trang web ở các tần số khác nhau. Các trang web nổi tiếng hơn, được biết đến thường xuyên đăng bài như https://lichngaytot.com sẽ được thu thập thông tin thường xuyên hơn trang web ít nổi tiếng hơn
Bạn có thể xem phiên bản được lưu trong bộ nhớ cache của trang trông như thế nào bằng cách nhấp vào mũi tên thả xuống bên cạnh URL trong SERP và chọn "Đã lưu trong bộ nhớ cache":
Bạn cũng có thể xem phiên bản thuần văn bản của trang web để xác định xem nội dung quan trọng của bạn có đang được thu thập thông tin và được lưu vào bộ nhớ cache một cách hiệu quả hay không.
 |
Các trang có bị xóa khỏi chỉ mục không?
Có, các trang có thể được xóa khỏi chỉ mục! Một số lý do chính khiến URL có thể bị xóa bao gồm:
- URL trả về lỗi "không tìm thấy" (4XX) hoặc lỗi máy chủ (5XX) - Điều này có thể là ngẫu nhiên (trang đã được di chuyển và chuyển hướng 301 không được thiết lập) hoặc cố ý (trang đã bị xóa và 404 để xóa nó khỏi chỉ mục)
- URL đã thêm thẻ meta noindex - Thẻ này có thể được thêm bởi chủ sở hữu site để hướng dẫn công cụ tìm kiếm bỏ qua trang từ chỉ mục của trang.
- URL đã bị phạt thủ công vì vi phạm Nguyên tắc quản trị trang web của công cụ tìm kiếm và kết quả là đã bị xóa khỏi chỉ mục.
- URL đã bị chặn thu thập thông tin bằng việc thêm mật khẩu bắt buộc trước khi khách truy cập có thể truy cập trang.
Nếu bạn tin rằng một trang trên site của bạn trước đây trong chỉ mục của Google không còn hiển thị nữa, bạn có thể gửi URL theo cách thủ công đến Google bằng cách điều hướng đến công cụ "Tìm nạp như Google" trong Search Console.
Ranking: Công cụ tìm kiếm xếp hạng URL như thế nào?
Làm cách nào để công cụ tìm kiếm đảm bảo rằng khi ai đó nhập truy vấn vào thanh tìm kiếm, họ nhận được kết quả có liên quan? Quá trình đó được gọi là xếp hạng hoặc thứ tự của các kết quả tìm kiếm có liên quan nhất đến một truy vấn cụ thể.
Để xác định mức độ liên quan, công cụ tìm kiếm sử dụng thuật toán, quy trình hoặc công thức mà thông tin được lưu trữ được truy xuất và sắp xếp theo những cách có ý nghĩa. Các thuật toán này đã trải qua nhiều thay đổi qua các năm để cải thiện chất lượng kết quả tìm kiếm.
Google, điều chỉnh thuật toán hàng ngày - một số bản cập nhật là các chỉnh sửa nhỏ, trong khi các bản cập nhật thuật toán cốt lõi / rộng khác được triển khai để giải quyết một vấn đề cụ thể, như Penguin để giải quyết spam liên kết.
Tại sao thuật toán thay đổi thường xuyên như vậy? Mặc dù Google không phải lúc nào cũng tiết lộ chi tiết về lý do họ làm những gì, chúng tôi biết rằng mục tiêu của Google khi thực hiện điều chỉnh thuật toán là cải thiện chất lượng tìm kiếm tổng thể. Đó là lý do tại sao, để trả lời các câu hỏi cập nhật thuật toán, Google sẽ trả lời bằng một số câu hỏi: “Chúng tôi đang cập nhật chất lượng mọi lúc”
Điều này cho thấy rằng, nếu site của bạn chịu sự điều chỉnh của thuật toán, hãy so sánh nó với Nguyên tắc Chất lượng của Google hoặc Hướng dẫn về chất lượng tìm kiếm, cả hai đều rất rõ về những gì công cụ tìm kiếm muốn.
Công cụ tìm kiếm muốn gì?
Các công cụ tìm kiếm luôn muốn có cùng một điều: để cung cấp câu trả lời hữu ích cho các câu hỏi của người tìm kiếm theo các định dạng hữu ích nhất. Nếu đó là sự thật, thì tại sao SEO là khác nhau hơn so với những năm trước?
Hãy suy nghĩ về nó với một người học một ngôn ngữ mới.
Lúc đầu, sự hiểu biết về ngôn ngữ rất thô sơ - “See Spot Run.” Theo thời gian, sự hiểu biết của họ bắt đầu sâu hơn, và họ học ngữ nghĩa— ý nghĩa đằng sau ngôn ngữ và mối quan hệ giữa các từ và cụm từ. Cuối cùng, với thực hành đủ, học sinh biết ngôn ngữ đủ tốt để thậm chí hiểu sắc thái, và có thể cung cấp câu trả lời cho các câu hỏi thậm chí mơ hồ hoặc không đầy đủ.
Khi các công cụ tìm kiếm mới bắt đầu học ngôn ngữ, việc sử dụng các thủ thuật và chiến thuật thực sự chống lại các nguyên tắc về chất lượng. Nhồi nhét từ khóa, ví dụ. Nếu bạn muốn xếp hạng cho một từ khóa cụ thể như " funny stories ", bạn có thể thêm các từ "funny stories" vào một số lần trên trang của mình và làm cho nó trở nên táo bạo, với hy vọng tăng thứ hạng của bạn cho cụm từ đó:
 |
Chiến thuật này được thực hiện cho những trải nghiệm người dùng khủng khiếp, và thay vì cười đùa với những câu chuyện cười vui nhộn, mọi người bị ném bom bởi văn bản khó chịu, khó đọc. Nó có thể đã làm việc trong quá khứ, nhưng điều này không bao giờ là những gì công cụ tìm kiếm muốn.
Vai trò liên kết trong SEO
Khi chúng ta nói về các liên kết, chúng ta có thể nói hai điều. Backlink hoặc "Inbound link" là các liên kết từ các website khác trỏ đến site của bạn, trong khi liên kết nội bộ là liên kết trên website của riêng bạn trỏ đến các trang khác của bạn (trên cùng một trang).
Liên kết có lịch sử đóng một vai trò lớn trong SEO. Rất sớm, các công cụ tìm kiếm cần giúp tìm ra URL nào đáng tin cậy hơn những người khác để giúp họ xác định cách xếp hạng kết quả tìm kiếm. Tính số lượng liên kết trỏ đến bất kỳ trang web cụ thể nào đã giúp họ thực hiện việc này.
Backlinks hoạt động rất giống với các giới thiệu WOM (Word-Of-Mouth) thực tế. Hãy lấy một quán cà phê giả định, cà phê của Jenny, làm ví dụ:
- Giới thiệu từ người khác = dấu hiệu tốt về thẩm quyền
Ví dụ: Nhiều người khác nhau đều nói với bạn rằng Cà phê của Jenny là tốt nhất trong thị trấn - Tự Giới thiệu bản thân = thiên vị, vì vậy không phải là một dấu hiệu tốt về thẩm quyền
Ví dụ: Jenny cho rằng cà phê của Jenny là tốt nhất trong thị trấn - Giới thiệu từ nguồn không liên quan hoặc chất lượng thấp = không phải là một dấu hiệu tốt về quyền lực và thậm chí có thể khiến bạn bị gắn cờ vì spam
Ví dụ: Jenny trả tiền để có những người chưa bao giờ ghé thăm quán cà phê của mình cho người khác biết nó tốt đến mức nào. - Không có giới thiệu = quyền không rõ ràng
Ví dụ: Cà phê của Jenny có thể tốt, nhưng bạn không thể tìm thấy bất kỳ ai có ý kiến để bạn không thể chắc chắn.
Đây là lý do tại sao PageRank được tạo. PageRank (một phần thuật toán cốt lõi của Google) là một thuật toán phân tích liên kết được đặt tên theo một trong những người sáng lập Google, Larry Page. PageRank ước tính tầm quan trọng của một trang web bằng cách đo lường chất lượng và số lượng các liên kết trỏ đến nó. Giả thiết là site càng liên quan, quan trọng và đáng tin cậy hơn thì càng có nhiều liên kết.
Các backlinks tự nhiên hơn bạn có từ các site có thẩm quyền cao (đáng tin cậy), tỷ lệ cược càng cao thì xếp hạng càng cao trong kết quả tìm kiếm.
Vai trò Content trong SEO
Sẽ không có điểm nào để liên kết nếu họ không trực tiếp tìm kiếm người khác. Cái gì đó là Content! Nội dung không chỉ là lời nói; đó là bất cứ điều gì có nghĩa là để được tiêu thụ bởi người tìm kiếm - có nội dung video, nội dung hình ảnh và tất nhiên là văn bản. Nếu các công cụ tìm kiếm là các máy trả lời, nội dung là phương tiện mà các công cụ cung cấp các câu trả lời đó.
Bất cứ khi nào ai đó thực hiện tìm kiếm, có hàng nghìn kết quả có thể, vậy làm cách nào để công cụ tìm kiếm quyết định những trang mà người tìm kiếm sẽ tìm thấy có giá trị? Một phần lớn trong việc xác định vị trí trang của bạn sẽ xếp hạng cho một truy vấn nhất định là nội dung trên trang của bạn phù hợp với ý định của truy vấn. Nói cách khác, trang này có khớp với các từ được tìm kiếm và giúp hoàn thành nhiệm vụ mà người tìm kiếm đang cố thực hiện không?
Vì điều này tập trung vào sự hài lòng của người dùng và hoàn thành nhiệm vụ, không có tiêu chuẩn nghiêm ngặt về thời lượng nội dung của bạn, bao nhiêu lần nên chứa từ khóa hoặc những gì bạn đưa vào thẻ tiêu đề của mình. Tất cả những người có thể đóng một vai trò trong một trang hoạt động như thế nào trong tìm kiếm, nhưng sự tập trung vào những người dùng sẽ đọc nội dung.
Ngày nay, với hàng trăm hoặc thậm chí hàng nghìn tín hiệu xếp hạng, ba tín hiệu hàng đầu vẫn tương đối ổn định: Liên kết đến site của bạn (là tín hiệu đáng tin cậy của bên thứ ba), Nội dung trên trang (nội dung chất lượng đáp ứng ý định của người tìm kiếm) và RankBrain.
RankBrain là gì?
RankBrain là thành phần học máy của thuật toán cốt lõi của Google. Học máy là một chương trình máy tính tiếp tục cải thiện dự đoán của nó theo thời gian thông qua các quan sát mới và dữ liệu đào tạo. Nói cách khác, nó luôn luôn học hỏi, và bởi vì nó luôn luôn học tập, kết quả tìm kiếm nên được liên tục cải thiện.
Ví dụ: nếu RankBrain nhận thấy URL xếp hạng thấp hơn cung cấp kết quả tốt hơn cho người dùng hơn URL xếp hạng cao hơn, RankBrain sẽ điều chỉnh kết quả đó, di chuyển kết quả có liên quan cao hơn và giảm hạng các trang có liên quan thấp hơn.
Điều này có ý nghĩa gì với SEO?
Bởi vì Google sẽ tiếp tục sử dụng RankBrain để quảng cáo nội dung hữu ích, có liên quan nhất, chúng tôi cần tập trung hoàn thành ý định của người tìm kiếm hơn bao giờ hết. Cung cấp thông tin và kinh nghiệm tốt nhất có thể cho những người tìm kiếm có thể truy cập trang và bạn đã thực hiện một bước đầu tiên lớn để hoạt động tốt trong thế giới RankBrain.
Chỉ số tương tác: tương quan, nhân quả hoặc cả hai?
Với xếp hạng của Google, số liệu tương tác có nhiều khả năng tương quan một phần và một phần nhân quả.
Khi chúng tôi nói số liệu tương tác , có nghĩa là dữ liệu đại diện cho cách người tìm kiếm tương tác với website của bạn từ kết quả tìm kiếm. Điều này bao gồm những thứ như:
- Số nhấp chuột (số lượt truy cập từ tìm kiếm)
- Thời gian trên trang (lượng thời gian khách truy cập đã bỏ đi trên một trang trước khi rời khỏi trang)
- Tỷ lệ thoát (phần trăm của tất cả các phiên website mà người dùng chỉ xem một trang)
- Pogo-sticking (bấm vào một kết quả hữu cơ và sau đó nhanh chóng trở lại SERP để chọn một kết quả khác)
Nhiều thử nghiệm, bao gồm khảo sát yếu tố xếp hạng của Moz , đã chỉ ra rằng các chỉ số tương tác tương quan với xếp hạng cao hơn, nhưng nhân quả đã được tranh luận sôi nổi. Số liệu tương tác tốt chỉ mang tính biểu thị của các website được xếp hạng cao? Hay các website được xếp hạng cao vì chúng có chỉ số tương tác tốt?
Những gì Google đã nói
Trong khi họ chưa bao giờ sử dụng thuật ngữ "tín hiệu xếp hạng trực tiếp", Google đã rõ ràng rằng họ hoàn toàn sử dụng dữ liệu nhấp chuột để sửa đổi SERP cho các truy vấn cụ thể.
Theo cựu Giám đốc Chất lượng Tìm kiếm của Google , Udi Manber:
“Bản thân xếp hạng bị ảnh hưởng bởi dữ liệu nhấp chuột. Nếu chúng tôi phát hiện ra rằng, đối với một truy vấn cụ thể, 80% người nhấp vào #2 và chỉ 10% nhấp vào # 1, sau một thời gian chúng tôi tìm ra có lẽ #2 là người muốn, vì vậy chúng tôi sẽ chuyển đổi."
Một bình luận từ cựu kỹ sư của Google Edmond Lau chứng thực điều này:
“Rõ ràng là bất kỳ công cụ tìm kiếm hợp lý nào cũng sẽ sử dụng dữ liệu nhấp chuột vào kết quả của riêng họ để đưa trở lại xếp hạng để cải thiện chất lượng kết quả tìm kiếm. Cơ chế thực tế về cách dữ liệu nhấp chuột được sử dụng thường là độc quyền, nhưng Google cho thấy rõ ràng rằng nó sử dụng dữ liệu nhấp chuột với các bằng sáng chế của nó trên các hệ thống như mục nội dung được điều chỉnh xếp hạng.”
Do Google cần duy trì và cải thiện chất lượng tìm kiếm, có vẻ như không thể tránh khỏi các chỉ số tương tác nhiều hơn mối tương quan, nhưng dường như Google thiếu số liệu tham gia gọi là "tín hiệu xếp hạng" vì các chỉ số đó được sử dụng để cải thiện chất lượng tìm kiếm và xếp hạng các URL riêng lẻ chỉ là sản phẩm phụ (byproduct) của điều đó.
Thử nghiệm nào đã được xác nhận
Các thử nghiệm khác nhau đã xác nhận rằng Google sẽ điều chỉnh thứ tự SERP để đáp ứng với sự tương tác của người tìm kiếm:
- Bài kiểm tra năm 2014 của Rand Fishkin dẫn đến kết quả #7 di chuyển lên vị trí # 1 sau khi nhận được khoảng 200 người nhấp vào URL từ SERP. Thật thú vị, cải tiến xếp hạng dường như bị cô lập với vị trí của những người đã truy cập liên kết. Vị trí xếp hạng tăng vọt ở Mỹ, nơi có nhiều người tham gia, trong khi vị trí xếp hạng vẫn thấp hơn trên trang Google Canada, Google Australia, v.v.
- Sự so sánh của Larry Kim về các trang hàng đầu và thời gian dừng trung bình trước và sau RankBrain dường như cho thấy thành phần máy học thuật toán của Google giảm vị trí xếp hạng của các trang mà mọi người không dành nhiều thời gian.
- Thử nghiệm của Darren Shaw đã cho thấy tác động của hành vi người dùng đối với các kết quả tìm kiếm địa phương và bản đồ.
Vì chỉ số tương tác của người dùng được sử dụng rõ ràng để điều chỉnh SERP về chất lượng và xếp hạng thay đổi vị trí dưới dạng sản phẩm phụ, nên SEO nên tối ưu hóa cho sự tương tác. Cam kết không thay đổi chất lượng mục tiêu của website, mà là giá trị của bạn đối với người tìm kiếm liên quan đến các kết quả khác cho truy vấn đó. Đó là lý do tại sao, sau khi không có thay đổi đối với trang của bạn hoặc backlink của trang, nó có thể giảm xếp hạng nếu hành vi của người tìm kiếm cho biết họ thích các trang khác tốt hơn.
Về xếp hạng các trang web, số liệu tương tác hoạt động như một trình kiểm tra thực tế. Các yếu tố khách quan như liên kết và nội dung xếp hạng trang đầu tiên, sau đó chỉ số tương tác giúp Google điều chỉnh nếu chúng không đúng.
Sự tiến hóa của kết quả tìm kiếm
Quay lại khi công cụ tìm kiếm thiếu rất nhiều sự tinh tế mà họ có ngày hôm nay, thuật ngữ "10 liên kết màu xanh" được đặt ra để mô tả cấu trúc phẳng của SERP. Bất kỳ khi nào tìm kiếm được thực hiện, Google sẽ trả về một trang có 10 kết quả không phải trả tiền, mỗi kết quả có cùng định dạng.
 |
Trong cảnh quan tìm kiếm này, giữ vị trí số #1 là quán quân của SEO. Nhưng rồi có chuyện xảy ra. Google đã bắt đầu thêm kết quả vào các định dạng mới trên các trang kết quả tìm kiếm của họ, được gọi là các tính năng SERP . Một số tính năng SERP bao gồm:
- Quảng cáo trả tiền
- Đoạn trích nổi bật (Featured snippets)
- Mọi người cũng hỏi hộp
- Gói địa phương (bản đồ)
- Bảng kiến thức (Knowledge panel)
- Liên kết site (Sitelinks)
Và Google luôn bổ sung thêm những tính năng mới. Nó thậm chí còn thử nghiệm với “Kết quả Zero SERPs”, một hiện tượng mà chỉ có một kết quả từ Sơ đồ tri thức được hiển thị trên SERP mà không có kết quả bên dưới nó trừ một tùy chọn để “xem thêm kết quả”.
Việc bổ sung các tính năng này gây ra một số hoảng sợ ban đầu vì hai lý do chính. Đối với một số người các tính năng này gây ra kết quả hữu cơ được đẩy xuống thêm trên SERP. Một sản phẩm phụ khác là ít người tìm kiếm đang nhấp vào kết quả không phải trả tiền vì các truy vấn khác đang được trả lời trên chính SERP.
Vậy tại sao Google sẽ làm điều này? Tất cả đều quay lại trải nghiệm tìm kiếm. Hành vi của người dùng cho thấy rằng một số truy vấn được thỏa mãn tốt hơn bởi các định dạng nội dung khác nhau. Lưu ý cách các loại tính năng SERP khác nhau phù hợp với các loại mục đích truy vấn khác nhau.
|
Mục đích truy vấn |
Tính năng SERP có thể được kích hoạt |
|
Thông tin |
Đoạn trích nổi bật |
|
Thông tin với một câu trả lời |
Sơ đồ tri thức / Câu trả lời tức thì |
|
Địa phương |
Gói bản đồ |
|
Giao dịch |
Mua sắm |
Chúng ta sẽ nói nhiều hơn về ý định tìm kiếm trong bài viết khác, nhưng bây giờ, điều quan trọng là phải biết rằng các câu trả lời có thể được gửi tới người tìm kiếm theo nhiều định dạng và cách bạn cấu trúc nội dung của mình có thể tác động đến định dạng mà nó xuất hiện trong tìm kiếm.
Tìm kiếm được bản địa hóa (Local search)
Công cụ tìm kiếm như Google có chỉ mục danh sách doanh nghiệp địa phương độc quyền của riêng nó, từ đó nó tạo ra kết quả tìm kiếm địa phương.
Nếu bạn đang thực hiện công việc SEO địa phương cho một doanh nghiệp có vị trí thực tế, khách hàng có thể truy cập (ví dụ: nha sĩ) hoặc doanh nghiệp đến thăm khách hàng của họ (ví dụ: thợ ống nước), đảm bảo rằng bạn xác nhận quyền sở hữu, xác minh và tối ưu hóa Google my Bussiness miễn phí
Khi nói đến kết quả tìm kiếm được bản địa hóa, Google sử dụng ba yếu tố chính để xác định xếp hạng:
- Mức độ liên quan
- Khoảng cách
- Sự nổi bật (Prominence)
Mức độ liên quan là doanh nghiệp địa phương phù hợp với những gì người tìm kiếm đang tìm kiếm. Để đảm bảo rằng doanh nghiệp đang làm mọi thứ có thể để có liên quan đến người tìm kiếm, hãy đảm bảo thông tin của doanh nghiệp được điền đầy đủ và chính xác.
Google sử dụng vị trí địa lý của bạn để phục vụ bạn tốt hơn các kết quả địa phương. Kết quả tìm kiếm địa phương cực kỳ nhạy cảm với sự gần nhau , trong đó đề cập đến vị trí của người tìm kiếm và / hoặc vị trí được chỉ định trong truy vấn (nếu người tìm kiếm bao gồm một).
Kết quả tìm kiếm không phải trả tiền nhạy cảm với vị trí của người tìm kiếm, mặc dù ít khi được phát âm như trong kết quả của gói địa phương.
Với sự nổi bật như một yếu tố, Google đang tìm cách thưởng cho các doanh nghiệp nổi tiếng trong thế giới thực. Ngoài sự nổi bật ngoại tuyến của một doanh nghiệp, Google cũng xem xét một số yếu tố trực tuyến để xác định xếp hạng địa phương, chẳng hạn như:
Nhận xét
Số lượng đánh giá của Google mà doanh nghiệp địa phương nhận được và tình cảm của những đánh giá đó có tác động đáng kể đến khả năng xếp hạng của họ trong kết quả địa phương.
Trích dẫn
"Trích dẫn kinh doanh" hoặc "danh sách doanh nghiệp" là tham chiếu dựa trên web đối với doanh nghiệp địa phương '' NAP '' (tên, địa chỉ, số điện thoại) trên nền tảng được bản địa hóa (Yelp, Acxiom, YP, Infogroup, Localeze, v.v.) .
Xếp hạng địa phương bị ảnh hưởng bởi số lượng và tính nhất quán của các trích dẫn kinh doanh địa phương. Google lấy dữ liệu từ nhiều nguồn khác nhau trong việc liên tục tạo chỉ mục doanh nghiệp địa phương của mình. Khi Google tìm thấy nhiều tham chiếu nhất quán về tên, vị trí và số điện thoại của doanh nghiệp, nó sẽ tăng cường "sự tin tưởng" của Google về tính hợp lệ của dữ liệu đó. Điều này sau đó dẫn đến việc Google có thể hiển thị doanh nghiệp với mức độ tin cậy cao hơn. Google cũng sử dụng thông tin từ các nguồn khác trên web, chẳng hạn như liên kết và bài viết.
Xếp hạng hữu cơ
Các phương pháp hay nhất về SEO cũng áp dụng cho SEO địa phương, vì Google cũng xem xét vị trí của trang web trong kết quả tìm kiếm không phải trả tiền khi xác định thứ hạng địa phương.
Trong chương tiếp theo, bạn sẽ tìm hiểu các phương pháp hay nhất trên trang để giúp Google và người dùng hiểu rõ hơn về nội dung của bạn.
Mặc dù không được Google liệt kê như là một yếu tố quyết định xếp hạng địa phương, vai trò của sự tham gia chỉ tăng lên khi thời gian trôi qua. Google tiếp tục làm phong phú thêm kết quả địa phương bằng cách kết hợp dữ liệu trong thế giới thực như thời gian ghé thăm phổ biến và thời lượng truy cập trung bình ...
 |
... và thậm chí cung cấp cho người tìm kiếm khả năng đặt câu hỏi về doanh nghiệp!
 |
Chắc chắn bây giờ hơn bao giờ hết, kết quả địa phương đang bị ảnh hưởng bởi dữ liệu trong thế giới thực. Tương tác này là cách người tìm kiếm tương tác và phản hồi với các doanh nghiệp địa phương, chứ không phải là thông tin thuần túy như liên kết và trích dẫn.
Vì Google muốn cung cấp các doanh nghiệp địa phương tốt nhất, có liên quan nhất cho người tìm kiếm, nên họ có ý nghĩa hoàn hảo để họ sử dụng các chỉ số tương tác thời gian thực để xác định chất lượng và mức độ liên quan.
Khi đã hiểu cách hoạt động của Google, giờ là lúc bạn tối ưu SEO đúng cách để đạt được mục tiêu SEO của bạn, và đây là bài viết tiếp theo bạn nên đọc: Hướng dẫn cơ bản về SEO dành cho người mớiDũng Hoàng, Seothetop
nguồn: Moz