Google đã thay thế người đứng đầu bộ phận tìm kiếm, Amit Singhal trong năm 2016, người đã đến khi Google mua lại Metaweb. Người sáng lập Metaweb, John Giannandrea, từng là phó chủ tịch của Google, phụ trách các nỗ lực AI của Google và sẽ đảm nhiệm vị trí trưởng phòng tìm kiếm tại Google.
Metaweb là công ty đã đưa Knowledge Graph (Sơ đồ tri thức) lên Google và điền vào kết quả tìm kiếm của Google bằng các Knowledge Panel (bảng kiến thức) liên quan đến các Entity (thực thể) xuất hiện trong các kết quả tìm kiếm đó.
Lần đầu tiên chúng tôi nhận ra các thực thể của Google vào năm 2012, trong video của họ Giới thiệu Sơ đồ tri thức:
Knowledge Graph là gì?
Ngôi nhà của các thực thể trên Google nằm trong Sơ đồ tri thức và Wikipedia cho chúng ta biết Knowledge Graph là gì:
Knowledge Graph là một cơ sở tri thức được Google sử dụng để nâng cao kết quả tìm kiếm của công cụ tìm kiếm với thông tin Semantic Search (tìm kiếm ngữ nghĩa) được thu thập từ nhiều nguồn khác nhau.
Hiển thị Sơ đồ tri thức đã được thêm vào công cụ tìm kiếm của Google vào năm 2012, bắt đầu từ Hoa Kỳ, đã được công bố vào ngày 16 tháng 5 năm 2012. Nó cung cấp thông tin có cấu trúc và chi tiết về chủ đề này ngoài danh sách các liên kết đến các website khác.
Mục tiêu là người dùng sẽ có thể sử dụng thông tin này để giải quyết truy vấn của họ mà không phải điều hướng đến các website khác và tự lắp ráp thông tin. Tóm tắt ngắn được cung cấp trong Sơ đồ tri thức thường được sử dụng làm câu trả lời được nói trong các tìm kiếm Google Hiện hành.
Google hiển thị thông tin về Thực thể từ Sơ đồ tri thức của mình trong Knowledge Panel mà nó hiển thị ở bên phải kết quả tìm kiếm. Nếu Google có thể xác định rằng một thực thể cụ thể được liên kết theo một cách nào đó với truy vấn mà chúng ta là người tìm kiếm nhập vào hộp tìm kiếm, nó sẽ cho chúng ta biết thêm về thực thể đó.
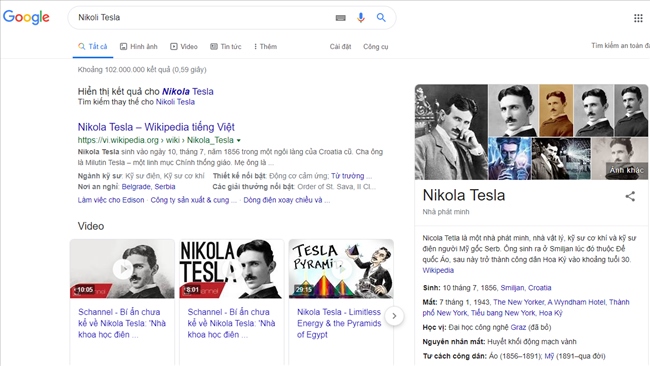
Knowledge Panel đó có thể bao gồm thông tin về các khía cạnh khác nhau của thực thể đó, từ các nguồn như Wikipedia, Freebase và các cơ sở tri thức khác. Google cũng có thể cho chúng ta biết về các thực thể khác mà mọi người đôi khi tìm kiếm ngoài thực thể chúng ta đã tìm kiếm. Dưới đây là kết quả bảng kiến thức trong Google cho Nikola Tesla:
 |
Vì vậy, Google hoạt động để cung cấp thông tin cho chúng ta về nhiều thực thể khác nhau có thể xuất hiện trong các truy vấn và tìm kiếm. Google có thể liên kết tên của các thực thể với các thực thể đó khi hiển thị bảng kiến thức cho chúng. Khi họ được hỏi về điều đó trong các truy vấn, Google có thể cố gắng nhận ra thực thể nào đang được yêu cầu cung cấp cho chúng ta thông tin đó.
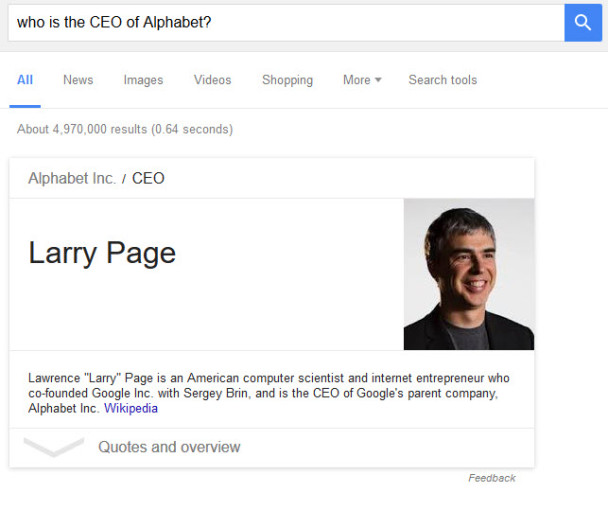
Ví dụ, khi Google được hỏi, thì ai là Giám đốc điều hành của Alphabet?, Nó cho chúng ta biết về Larry Page và cung cấp thông tin về anh ta (trong trường hợp này là từ Wikipedia).
 |
Một bằng sáng chế của Google đã được cấp tập trung vào sự công nhận thực thể và dự đoán các thực thể khi các phần câu có thể đề cập đến các thực thể đó. Các cơ sở kiến thức tạo nên Sơ đồ tri thức của Google chứa đầy các câu về các thực thể, có khả năng là nguồn gốc của nhiều câu trả lời cho các câu hỏi về chúng.
Bằng sáng chế: Entity identification model training
Entity identification model training (Đào tạo mô hình nhận dạng thực thể)
Bằng sáng chế cung cấp một số ví dụ về cách nó có thể dự đoán danh tính của các thực thể đã được tham chiếu trong các câu hoàn chỉnh, bằng cách thu thập thông tin về các thực thể đó và sau đó sử dụng thông tin đó từ các câu đó để xác định một thực thể có thể được hỏi về. Đây là một ví dụ từ bằng sáng chế:
Hệ thống nhận dạng thực thể có được các câu hoàn chỉnh mà mỗi câu bao gồm văn bản thực thể tham chiếu đến một thực thể đầu tiên. Một ví dụ hoàn chỉnh câu có thể là, Năm 1890, Tổng thống Hoa Kỳ là Benjamin Harrison. Hồi Trong bối cảnh của câu ví dụ này, văn bản thực thể, Tổng thống Hoa Kỳ, người đề cập đến người đó, “Benjamin Harrison”. Đối với mỗi câu hoàn chỉnh, hệ thống nhận dạng thực thể mô phỏng việc gõ câu và cung cấp các phần của câu cho mô hình nhận dạng thực thể. Mô hình nhận dạng thực thể xác định một thực thể dự đoán cho từng phần của câu mà nó nhận làm đầu vào.
Bằng sáng chế dựa trên ví dụ này bằng cách cho chúng tôi biết làm thế nào thông tin từ một câu hoàn chỉnh có thể được sử dụng để xác định một thực thể cụ thể:
Hệ thống nhận dạng thực thể có thể tiếp tục nhập các phần của câu hoàn chỉnh, cập nhật mô hình nhận dạng thực thể cho từng phần dựa trên độ chính xác của dự đoán. Ví dụ, mô hình nhận dạng thực thể có thể nhận được, “In 1890, the President of the Un,” làm đầu vào. Mặc dù đầu vào này vẫn có thể đề cập đến nhiều thực thể, ví dụ, Benjamin Harrison, Tổng thống Hoa Kỳ năm 1890 hoặc William Ellison Bogss, Chủ tịch Đại học Georgia vào năm 1890, mô hình nhận dạng thực thể có thể dự đoán chính xác về Benjamin Harrison cho điều này phần của câu hoàn chỉnh. Trong tình huống này, ví dụ, mô hình nhận dạng thực thể có thể được cập nhật, bằng cách tăng độ tin cậy và / hoặc khả năng rằng Benjamin Harrison sẽ được xác định cho một câu bắt đầu “In 1890, the President of the Un,” .
Bằng sáng chế là:
Đào tạo mô hình nhận dạng thực thể
Được phát minh bởi: Maxim Gubin, Sangsoo Sung, Krishna Bharat và Kenneth W. Dauber
Được gán cho: Google
Bằng sáng chế Hoa Kỳ 9,251,141
Cấp ngày 2 tháng 2 năm 2016
Nộp: ngày 12 tháng 5 năm 2014
Tóm lược
Phương pháp, hệ thống và bộ máy, bao gồm các chương trình máy tính được mã hóa trên phương tiện lưu trữ máy tính, để đào tạo mô hình nhận dạng thực thể. Trong một khía cạnh, một phương thức bao gồm thu được nhiều câu hoàn chỉnh mà mỗi câu bao gồm văn bản thực thể tham chiếu đến một thực thể đầu tiên; cho mỗi câu hoàn chỉnh trong số nhiều câu hoàn chỉnh: cung cấp một phần đầu của câu hoàn chỉnh làm đầu vào cho một mô hình nhận dạng thực thể xác định một thực thể dự đoán cho phần đầu tiên của câu hoàn chỉnh, phần đầu tiên ít hơn tất cả các câu hoàn chỉnh kết án; so sánh thực thể dự đoán với thực thể đầu tiên; và cập nhật mô hình nhận dạng thực thể dựa trên việc so sánh thực thể dự đoán với thực thể đầu tiên.
Những điểm quan trọng
Công cụ tìm kiếm như Google và Bing đang chuyển đổi từ việc cung cấp thông tin cho người tìm kiếm từ một chỉ mục các trang trên Web để cung cấp thông tin từ một chỉ mục dữ liệu họ tìm thấy trên Web. Điều này có nghĩa là trả lời trực tiếp các câu hỏi cho người tìm kiếm và là nguồn thông tin đang tập trung vào việc lập chỉ mục thông tin. Thông tin về các thực thể có thể được tìm thấy trong các nguồn như Sơ đồ tri thức của Google, có thể được sử dụng làm nguồn đào tạo(training) để xây dựng các mô hình nhận dạng thực thể, như được mô tả trong bằng sáng chế này.
Bằng sáng chế cung cấp một số hoặc ví dụ về cách nó có thể sử dụng thông tin câu hoàn chỉnh để xây dựng các mô hình có thể giúp công cụ tìm kiếm nhận ra các thực thể cụ thể. Một trong số đó bao gồm câu “Tòa nhà cao nhất thế giới là Burj Khalifa”, và thông tin đó thay đổi như thế nào khi bạn nói về thế giới vào năm 1931, khi tòa nhà cao nhất thế giới là Tòa nhà Empire State.
Bằng sáng chế cho chúng ta biết rằng các mô hình để nhận ra các thực thể mà nó xây dựng có thể sử dụng một phần câu, trả về thông tin về người cao nhất thế giới và ngọn núi cao nhất thế giới. Đọc toàn bộ bằng sáng chế này được khuyến nghị để biết thêm chi tiết về cách các mô hình giúp nhận biết các thực thể có thể được xây dựng từ các nguồn như Sơ đồ tri thức của Google.
Thật thú vị khi một trong những nhà phát minh được liệt kê trong bằng sáng chế này là Krishna Bharat, người đã thực hiện rất nhiều công việc đằng sau Google News - nơi khác mà chúng ta thấy các thực thể mọc lên thường xuyên. Nếu Google đang tìm hiểu về các thực thể và cách trả lời các câu hỏi về chúng, thì có thể đó là một phần bằng cách học hỏi từ Tin tức về những gì chúng dự định.
Chúng tôi đã nghe về Deep Mind của Google và những nỗ lực của họ để đọc CNN và Daily Mail như là nguồn đào tạo để tìm hiểu về thế giới . Họ có thể tìm thấy thông tin về rất nhiều thực thể từ những nguồn đó.
Và, với John Giannandrea, cựu người sáng lập Metaweb, đảm nhiệm vị trí trưởng bộ phận tìm kiếm tại Google, chúng ta có thể thấy nhiều thông tin Sơ đồ tri thức hơn vào kết quả tìm kiếm trong tương lai và thêm thông tin về các thực thể điền vào các kết quả đó. Tương lai của Google có thể liên quan đến rất nhiều entity.
tác giả BILL SLAWSKI